
In the ever-evolving landscape of artificial intelligence and machine learning, the term “interpretability” has emerged as a cornerstone in the development and application of these technologies. As data scientists, AI researchers or machine learning engineers, we constantly strive to create models that are not only accurate and efficient but also understandable and trustworthy. This blog post delves into the realm of interpretable machine learning, a critical area that bridges the gap between complex, often opaque models and the need for clarity and comprehensibility in their decisions and predictions.
The journey of making “black box” models explainable is not just a technical endeavor; it’s a necessary step towards responsible AI development. As these models increasingly influence various aspects of life, from healthcare diagnostics to financial decision-making, the imperative for transparency and understanding of their inner workings becomes paramount. This guide aims to provide an in-depth exploration of the methods and techniques to achieve interpretability in machine learning. We will traverse from the foundational concepts to the sophisticated methods used in interpreting complex models, particularly neural networks.
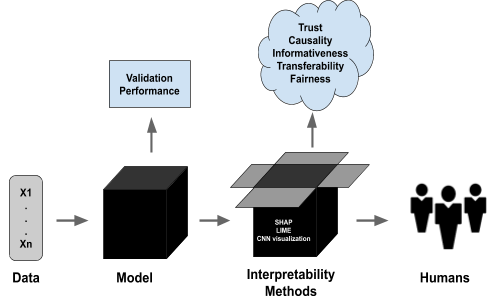
For you, this guide offers a comprehensive overview of interpretable machine learning. We will dissect various models and methods, providing insights and practical knowledge that can be applied in your research and projects. Whether you are looking to improve the transparency of your models, comply with regulatory requirements, or simply have a keen interest in the ethics of AI, this guide serves as a valuable resource in your professional toolkit.
In the following sections, we will start by defining interpretability in the context of machine learning, followed by a discussion on its importance. We will then delve into different models and methods, including Linear Regression, Logistic Regression, Decision Trees, Global and Local Model-Agnostic Methods, and techniques for interpreting neural networks. Each section aims to not only explain the theoretical aspects but also provide practical insights and examples, enhancing your understanding and application of these concepts.
As we embark on this exploration of making black box models explainable, let’s first dive into the core of this subject — understanding what interpretability in machine learning truly means and why it’s a critical component in the field of AI.
Interpretability in machine learning is a concept that, at its core, involves making the behavior and predictions of a model understandable to humans. It’s about bridging the gap between the complex, mathematical world of algorithms and the intuitive, logical realm of human reasoning. This section sheds light on what interpretability means in the context of machine learning and the different forms it can take.
At its simplest, interpretability refers to the extent to which a human can comprehend the reasons behind a model’s decision or prediction. This doesn’t necessarily mean understanding every mathematical detail but rather grasping the logic and factors the model considers when making a decision. For instance, in a credit scoring model, interpretability would mean being able to understand why the model approves or rejects a credit application — is it because of the applicant’s credit history, income level, or some other factor?
Interpretability in machine learning models can be broadly classified into two categories:
Both types of interpretability serve the same purpose — to make machine learning models more transparent and their decisions more understandable. The choice between intrinsic and post-hoc interpretability often depends on the complexity of the task at hand and the trade-off between model performance and interpretability.
In the next sections, we’ll explore the importance of interpretability in greater detail, understand why it’s crucial in various applications, and then dive into the specifics of different interpretable models and methods.
The significance of interpretability in machine learning extends far beyond a mere technical requirement; it encompasses ethical, legal, and practical dimensions. This section delves into the reasons why interpretability is not just desirable but essential in many scenarios involving machine learning models.
In conclusion, the importance of interpretability in machine learning is multifaceted, addressing ethical considerations, legal compliance, and practical necessities. It’s a cornerstone for building models that are not only powerful and accurate but also fair, transparent, and accountable.
In the following sections, we will explore various interpretable models and methods that help achieve these objectives, starting with intrinsic models like Linear Regression, Logistic Regression, and Decision Trees.
In the realm of machine learning, certain models inherently offer a level of interpretability. We will explore three such models: Linear Regression, Logistic Regression, and Decision Trees, each known for their transparency in decision-making processes.
Linear regression is one of the most straightforward and widely used statistical techniques for predictive modeling. It establishes a linear relationship between a dependent variable and one or more independent variables.
The general form of a linear regression model is:
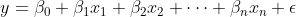
Where:
The coefficients $\beta_1, \beta_2, …, \beta_n$ represent the change in the dependent variable for a one-unit change in the corresponding independent variable, holding all other variables constant. This direct relationship provides a clear and interpretable model.
The main advantage of linear regression models is their simplicity. These models use linear equations that are easy to interpret at a basic level (such as the weights). That’s why linear models are widely used in academic fields like medicine, sociology, psychology, and other quantitative research areas. For instance, in medicine, it’s important not only to predict a patient’s clinical outcome but also to measure the impact of a drug while considering factors like sex, age, and other features in an understandable way.
Logistic regression, often used for binary classification, models the probability of a binary response based on one or more predictor variables.
The logistic regression model uses the logistic function to model a binary dependent variable. The formula is given by:
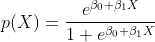
Where:
The coefficients in logistic regression indicate the relationship between each predictor and the probability of the outcome, offering interpretability in terms of how predictor variables affect the probability.
The way we understand the weights in logistic regression is different from how we understand the weights in linear regression. In logistic regression, the outcome is a probability between 0 and 1. This means that the weights don’t have a linear impact on the probability anymore. Instead, the weighted sum is transformed using the logistic function to determine the probability.
Decision trees are a non-parametric supervised learning method used for classification and regression. They are intuitive and easy to visualize.
A decision tree splits the data into branches at decision nodes, which are based on feature values. Each leaf node in the tree represents a decision outcome. This structure makes it easy to follow the logic of the model — by tracing a path from the root to a leaf, we can understand the decision-making process.
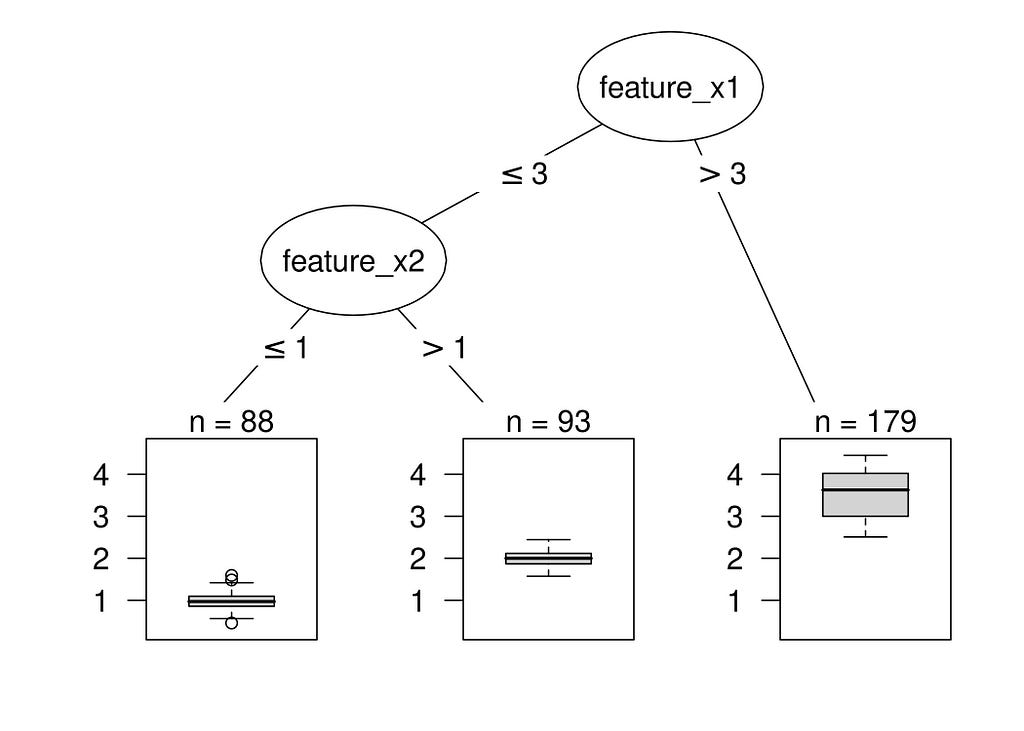
In the next sections, we will explore model-agnostic methods for interpreting more complex models, starting with global methods like Partial Dependence Plots and Global Surrogate Models.
When dealing with complex machine learning models, global model-agnostic methods provide a way to understand the model’s overall behavior. These methods are not specific to any particular type of model and can be applied universally. We will discuss two such methods: Partial Dependence Plots (PDP) and Global Surrogate Models.
Partial Dependence Plots are a popular tool for interpreting the results of complex models. They show the relationship between a feature (or features) and the predicted outcome, averaged over the joint distribution of the other features in the model.
A PDP illustrates how a feature affects the prediction on average, assuming the other features remain constant. This is helpful in understanding the effect of a single feature or a combination of features on the prediction, disregarding interactions between features.
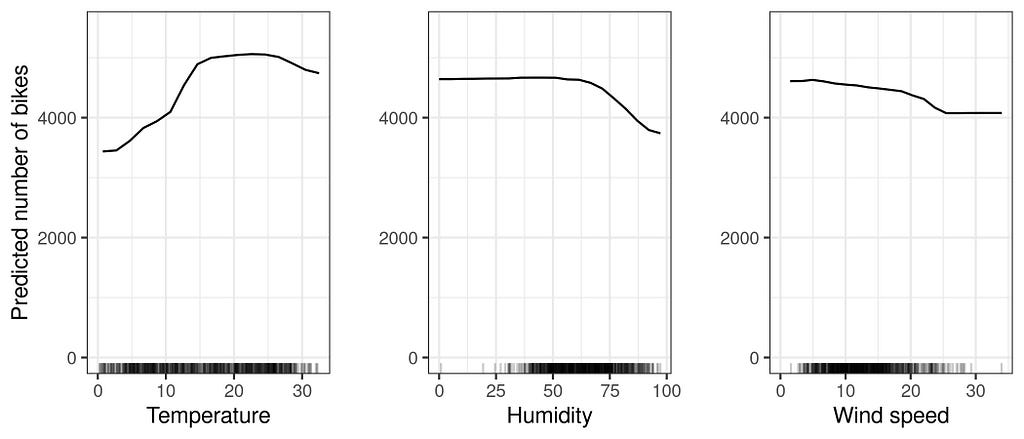
In above picture you can see the PDPs for the bike count prediction model and weather variables (temperature, humidity, and wind speed). The temperature has the most significant impact on bike rentals. As the temperature increases, more bikes are rented. This trend continues until it reaches 20 degrees Celsius, after which it levels off and slightly decreases at 30 degrees Celsius. The marks on the x-axis represent the distribution of the data.
Global surrogate models approximate the predictions of a complex model with a simpler, more interpretable model.
The idea behind a global surrogate model is to train a simpler model (like a linear regression or a decision tree) to mimic the predictions of the complex model. The surrogate model, being simpler and more interpretable, can then provide insights into how the complex model makes decisions.
In the following section, we will explore local model-agnostic methods, which focus on interpreting individual predictions, rather than the overall behavior of the model. This includes techniques such as Local Surrogate (LIME) and Shapley Values.
While global model-agnostic methods provide an overall understanding of a model, local model-agnostic methods offer explanations for individual predictions. This is particularly useful in complex models where understanding specific decisions is crucial. We will discuss two prominent techniques: Local Surrogate (LIME) and Shapley Values.
Local Interpretable Model-agnostic Explanations (LIME) is a technique that explains individual predictions of any machine learning model by approximating it locally with an interpretable model.
LIME works by perturbing the input data and observing the changes in the model’s predictions. For a given instance, LIME generates a new dataset consisting of perturbed samples and the corresponding predictions. Then, it trains an interpretable model, like a linear regression or decision tree, on this new dataset. The interpretable model is meant to be a good approximation of the complex model’s behavior in the vicinity of the instance being explained.
Shapley Values, originating from cooperative game theory, provide a way to fairly distribute the “payout” (prediction) among the “players” (features).
The Shapley Value of a feature value is the average marginal contribution of that feature value over all possible feature combinations. In the context of machine learning, it quantifies how much each feature contributes to the difference between the actual prediction and the average prediction.
In the next section, we will delve into the challenges and techniques of interpreting neural networks, which represent some of the most complex models in machine learning.
Neural networks, particularly deep learning models, are known for their exceptional performance across a wide range of complex tasks. However, their highly interconnected structure makes them one of the most challenging models to interpret. This section explores the intricacies of interpreting neural networks and the techniques developed to address these challenges.
Despite these challenges, several techniques have been developed to make neural network models more interpretable:
As neural network models continue to evolve, so do the techniques for interpreting them. Ongoing research is focused on developing more sophisticated and user-friendly methods for interpretation. This includes integrating interpretability directly into the model architecture and developing new visualization techniques that can provide clearer insights into the complex workings of these powerful models.
In conclusion, interpreting neural networks is a challenging but crucial part of machine learning. As we develop more advanced models, the need for effective interpretation methods will only grow. The techniques discussed here represent just the beginning of what is a rapidly evolving field, holding the promise of making even the most complex models understandable.
The journey through the landscape of interpretable machine learning has taken us from the basic concepts of interpretability to the complexities of interpreting advanced neural networks. This guide aimed to demystify the process of making “black box” models explainable, providing data scientists and AI researchers with the tools and knowledge to bring transparency and understanding to their machine learning models.
As the field of machine learning continues to evolve, the demand for interpretable models will only increase. The development of new techniques and the refinement of existing ones will play a crucial role in making machine learning models not only more effective but also more accountable and trustworthy. The ongoing dialogue between technology and ethics, between complexity and clarity, will shape the future of interpretable machine learning, ensuring that these powerful tools are used responsibly and for the benefit of all.
This guide is an invitation to delve deeper into the world of interpretable machine learning. It encourages a mindset that values not just the performance but also the understandability of your models. As you continue to develop and deploy machine learning solutions, remember that the pursuit of interpretability is not just a technical challenge but a commitment to ethical and responsible AI development.
Interpretable Machine Learning
<hr><p>Decoding the Black Box: A Comprehensive Guide to Interpretable Machine Learning was originally published in Dev Genius on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>